
杓谷技研というマーケティング支援会社の代表を務めております杓谷 匠(しゃくや たくみ)と申します。この記事では、アタラ株式会社会長の佐藤康夫さんのご協力のもと、2024年9月5日(木)に連載を開始した「インターネット広告創世記 ~Googleが与えたインパクトから発展史を読み解く〜」の第18話をお届けします。なお、本連載は、株式会社インプレスが運営するWeb担当者Forumでも同時に公開しています。
前回の記事はこちらです。
杓谷:楽天が佐藤さんの所属するInfoseek Japanを買収をした頃、Google日本語版のサービスが始まりました。佐藤さんはGoogleから声がかかり、サンフランシスコ近郊のマウンテンビューにあるGoogle本社を訪問し、2001年10月にGoogle日本法人のセールス&オペレーション・ディレクターとして入社しました。
佐藤:Googleの検索エンジンが当時いかに革新的だったかを読者のみなさまにご理解いただくために、Google以前の検索エンジンの技術と、検索エンジンに関連するインターネット広告がどのようなものであったかを紹介しておきたいと思います。
「ロボット型」と「ディレクトリ型」の検索エンジン
佐藤:第9話でも触れましたが、デジタルガレージがソフトバンクの孫さんにYahoo!を取られてしまったあとInfoseekを選んだ理由は、Infoseekが「ロボット型」の検索エンジンを開発していたからでした。
「ロボット型」の検索エンジンは今のGoogleの検索エンジンと基本的に同じ仕組みで、「クローラー」(Crawler)と呼ばれるロボットがウェブサイトのリンク構造を辿ってインターネット上のありとあらゆるウェブページを巡回して検知し、検索エンジンのデータベースに整理された状態で格納します。この一連の作業のことを「インデックス化」と言うのですが、「クローラー」に「インデックス化」されることで初めてウェブページは検索結果に表示できるようになります。逆に言うと、ウェブページが出来たばかりなどの理由で「クローラー」が巡回していない場合、「インデックス化」が済んでいないのでウェブページは検索結果には表示されません。
この「インデックス化」の過程でHTMLに記述されたテキスト情報などを元にウェブページ単位でコンテンツの内容を解析しているので、検索語句に関連するウェブページを検索結果に表示させることができるわけです。
一方で、Yahoo! JAPANは「ディレクトリ型」と呼ばれる検索エンジンの仕組みを採用していました。膨大な数のウェブサイトが存在する今の時代には信じられないかもしれませんが、当時のYahoo! JAPANには「サーファー」と呼ばれる人がいて、人の手でウェブサイトを「ビジネスと経済」「コンピューターとインターネット」などのディレクトリ(≒カテゴリ)に分類していました。
「ロボット型」の検索エンジンが検索語句に関連するウェブページのリンクを表示させるのに対し、「ディレクトリ型」の検索エンジンの検索結果には、検索語句に関連するディレクトリを表示させていました。言ってしまえばサイト内検索のようなものですね。
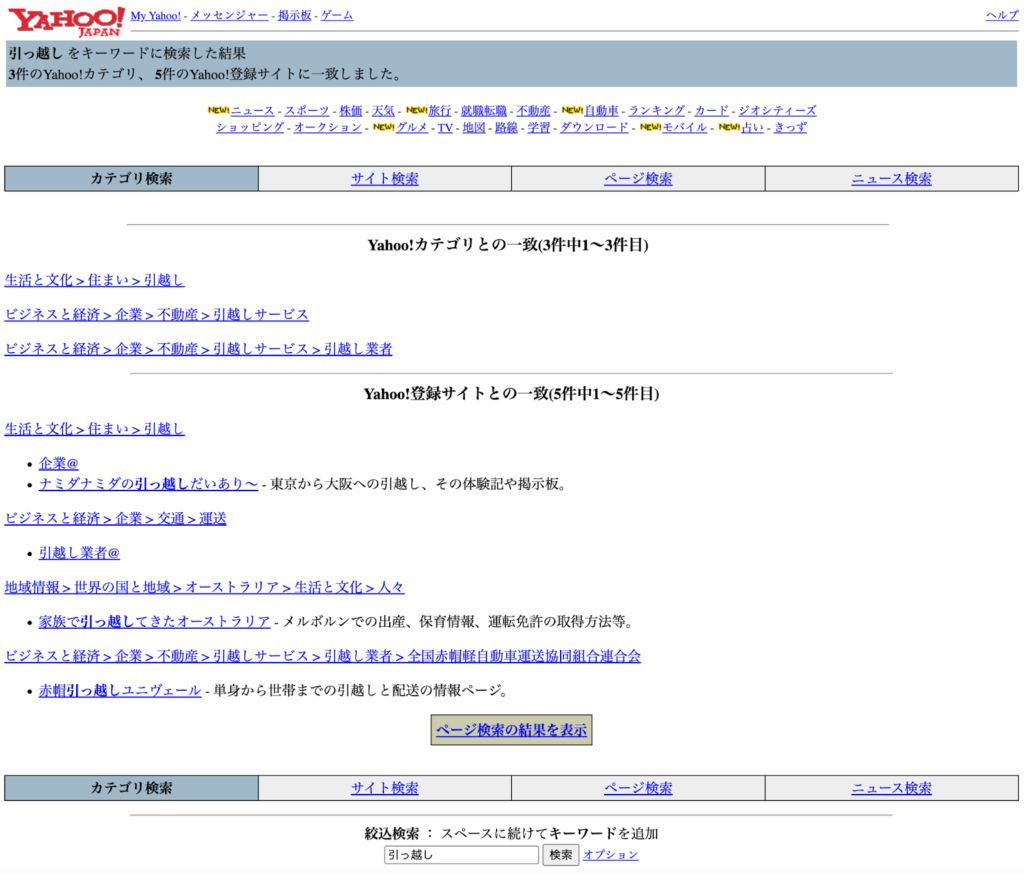
Yahoo! JAPANで「引っ越し」と検索した時の「ディレクトリ型」検索エンジンの検索結果(1997年1月)
検索エンジンの仕組み|ロボット型とディレクトリ型の特徴を比較【図解】
https://webtan.impress.co.jp/e/2021/04/21/38544
佐藤:米Yahoo!・Yahoo! JAPANともにロボット型の検索エンジンは開発していなかったので、デジタルガレージとしては、Infoseekが技術力でYahoo!に勝ると考えていたと思います。
僕がInfoseekを始めた頃は、ロボット型検索エンジンは早稲田大学の「千里眼」、東大の「ODiN」、京大の「RCAAU Mo-n-do-u」(問答)などがありました。これらの検索エンジンを開発していたエンジニアの多くが後にGoogleに移籍しました。
企業が開発していたロボット型の検索エンジンとしては第11話でも紹介したNTTの「goo」や、東芝の「フレッシュアイ」(FreshEYE)などがあり、「フレッシュアイ」は他のロボット型の検索エンジンに比べてクローラーが巡回する頻度が高く、30分に1回情報が更新され、名前通り情報がフレッシュなことを売りにしていました。情報量の多さではDECのAltaVista(アルタビスタ)が圧倒的でした。
東芝の「フレッシュアイ」(FreshEYE)。クローラーの更新頻度が30分なのが特長だった。
技術は高度なのにディレクトリ検索に負けてしまうロボット型検索
佐藤:ロボット型検索エンジン全盛の現在から振り返ると、ディレクトリ検索よりもロボット型検索エンジンの方が性能が良さそうに思えますが、当時の検索エンジンは第1世代だったので、並列処理ができませんでした。そのため、クローラーがインターネット上のウェブサイトを巡回する頻度も低く、情報の更新が1ヶ月に1度というのもざらで、検索結果に表示された情報が実際のウェブサイトの内容よりも古くなってしまうといった技術的な問題を抱えていました。
例えば「トヨタ」と検索するとトヨタ自動車の会社のページが一番最初に表示されるべきなのですが、当時のロボット型検索エンジンだと検索結果のトップに来ないわけです。広告代理店から「何でトヨタで検索してもトヨタが上に来ないんだよ。こんなんじゃ検索結果の広告が売れないよ!」といったクレームをたくさんもらいました。Yahoo! JAPANのディレクトリ型検索では、人の手で検索結果をまとめているので、必ずトヨタ自動車のウェブサイトが上位に出てきます。
また、当時のロボット型検索エンジンはスパム判定の精度が低いという問題もありました。1999年1月にプロレスラーとして有名だったジャイアント馬場さんが亡くなられてニュースになったのですが、その時に「ジャイアント馬場」と検索すると、検索結果が全部アダルトサイトになってしまったんです。
ユーザーには見えない文字の色で「ジャイアント馬場」というテキストをたくさん仕込むと、実態としてはアダルトサイトでもジャイアント馬場さん関連のコンテンツがあるウェブサイトだと判断してしまい、アダルトサイトが上位に表示されてしまったんです。11話に登場したエンジニアのジョナが懸命に対処していたのを覚えています。ディレクトリ検索では人の目でコンテンツを確認しているのでこのようなことは起こりません。
技術としてはロボット型検索の方が高度なのに、人海戦術のディレクトリ型検索に負けてしまうというカッコ悪さがありました。当時はウェブサイトの数自体が今に比べて多くなかったこともロボット型検索エンジンに不利な要因のひとつだったと思います。結局Infoseekもディレクトリを作らざるをえませんでした。
検索語句はエロワードだらけ!?
佐藤:僕は、Infoseek時代に広告の収益を高めるために、どうやって魅力的なコンテンツを増やしてInfoseekのページビューを増やしていくかを常に考えていました。Infoseekが持っているコンテンツってなんだろうと考えた時に真っ先に思い当たったのは検索エンジンにユーザーが打ち込む検索語句でした。検索エンジンの中では、今世の中で何が流行ってるかがリアルに分かり、流行の息吹が検索語句に表れてくるわけです。これをランキング形式にして世の中に出していくことを考えました。今年検索された女優ナンバーワンとか言って、勝手にアワードを作って式典をやろうよ、などというアイデアも出て社内で盛り上がっていました。実現はしなかったんですが(笑)。
そこで、実際にInfoseekの検索エンジンに入力された検索語句を調べてみたのですが、検索数の多い順に検索語句を並べてみると、上位のほとんどがエロワードだらけだったことに大きな衝撃を受けました。これは実は意外に知られていないことかもしれません。検索エンジンとは、世の中の営みがすべて吐き出されてしまうすごい入れ物というか、すごい存在だなと思いましたね。人々の欲望がそのまま検索語句として表れてしまうわけですから。こんなところに需要があるのか、と驚くような検索語句がたくさんありました。検索語句の魅力にすっかり取り憑かれてしまいました。
第6話で紹介しましたが、伊藤穰一が考察していたインターネットがもたらすであろう社会的な変化として「情報発信を誰でもできるようになり、個人がエンパワーメントされる」という一節がありましたが、検索エンジンも個人のエンパワーメントの一環だなと強く思いましたね。
日本人はタイピングしないから検索エンジンは流行らない?
佐藤:インターネットが登場して間もない頃、「日本人はタイピングしない。だから、検索エンジンは普及しない。ディレクトリでいいんだ」なんてことがよく言われていました。今聞くと暴論に聞こえますが、当時の一般の方がパソコンのキーボードをブラインドタッチできるのかできないのか、という懸念は確かにありました。
こうした背景から、僕が中心となってロボット型検索エンジンを提供する複数社の共同で、検索エンジンは便利だということをアピールするためのイベントを秋葉原で開催することになりました。各社の代表者が出席して、「7月の花火大会」などのお題を出した時に、どこの検索エンジンがもっとも関連性の高いウェブサイトを返すかを争うという企画でした。実は、「7月の花火大会」といった検索語句は、ニーズがかなり限定されているのでYahoo! JAPANのようなディレクトリ検索だと対応が難しかったりしたんです。

1998年7月に行われた「Internet Show in 秋葉原」に佐藤さんが出演したセッションが紹介されている
出典:PC Watch『98 Internet Show in AKIHABARA』
佐藤:地道ではありましたが、ロボット型検索エンジン自体への理解を広めることと、検索エンジンに検索語句を入力する方法を啓蒙する必要があった時代でしたね。確か1997年のことだったと思うのですが、当時アスキーがパソコン関連の深夜番組を持っていて、その番組でも検索エンジン特集として実演デモを行なったりしました。
検索エンジンの開発は儲からない
佐藤:2001年にInfoseekを辞めてGoogleに移籍する時に、第11話で登場したスーパーエンジニアのジョナをGoogleに誘ったのですが、「検索エンジンは儲からないから」という理由で断られてしまいました。Infoseekでやってみていかに検索エンジンの開発が大変かを身に沁みて分かっていたんですね。
Infoseekでは、1997年5月から「Ultraseek日本語版」という日本語検索エンジンサービスを提供していたのですが、Sunの「Ultra Enterprise 3000」というサーバーをインフラとして使っていました。このサーバーがとても高性能だったので、処理できるデータの量が飛躍的に向上したのですが、普通に買うと1000万円ほどする高価な代物でした。Infoseekがこのサーバーを利用できたのはSunに出資してもらった立場だったからという特別な理由があってのことでした。
「Ultraseek日本語版」は、それ以前の検索エンジンとは比べ物にならない程素晴らしく、殆ど毎日のように情報が更新され、扱う情報量も飛躍的に増えたので利用者がどんどん増え、それまで全然伸びなかったページビューがあれよあれよという間に100万ページビュー/日を達成したのを覚えています。これを開発したのが、エコシスでジョナと同僚だったスーパーエンジニアのテッド・クロスマンで私にとっては救世主のようでした。それ以来彼は「ウルトラの父」と呼ばれていたのです。
infoseek Japanが新検索エンジンサービス「Ultraseek日本語版」を5月6日より開始https://internet.watch.impress.co.jp/www/article/970423/infoseek.htm

1997年9月号の『月刊サンワールド』に掲載された「Ultra Enterprise 3000」。よく見るとサーバーの名前に因んでウルトラマンの人形が置かれている。(佐藤さん所蔵)

「Ultra Enterprise 3000」を使って飛躍的に向上したInfoseekの検索エンジンの処理能力
出典:1997年9月号の『月刊サンワールド』(佐藤さん所蔵)
佐藤:ユーザー数やクローリングするウェブページの数が増えるに従って必要となるサーバーの数は増えていくので、一から検索エンジンを開発するにはとてもコストが見合わないだろう、というのがジョナの見立てだったと思います。検索エンジンに対する当時のエンジニアの考え方としては、このジョナの考え方が一般的だったと思います。実際、僕がGoogleに移籍する2001年頃には米Infoseek本社も検索エンジンの開発を停止することを決定していました。
リンク構造を加味した「Page Rank」で精度が飛躍的に向上
佐藤:Googleは、1998年9月にスタンフォード大学の博士課程に在籍していたラリー・ペイジとサーゲイ・ブリン(※日本語ではセルゲイ・ブリンと表記されることもあるが、本人は英語読みでサーゲイと呼ばれている)の二人によって設立されました。

2003年に撮影されたGoogle創業者のラリー・ペイジ(左)とサーゲイ・ブリン(右)
出典:Google page brin.jpg is under CC BY-2.0
{kind=link}
Googleの検索エンジンはInfoseekと違い、一般的なパソコンで使われるようなCPUを大量に使って並列処理させる方式を採用しました。この方式だと、高価なサーバーを利用することなく高性能な処理を実現でき、低コスト化が実現できます。また、複数のクローラーを並行して走らせることできるので、情報の更新頻度も高く、最新の情報を検索結果に表示させることが可能になりました。

コンピューターヒストリーミュージアムに保管されたGoogleの初代サーバーラックGoogle’s First Production Server (1999) rack – Computer History Museum is under CC BY-SA 2.0
{kind=link}
佐藤:加えて、当時のロボット型検索エンジンのアルゴリズムは、検索語句とウェブページの内容の関連性に基づいて検査結果の順位を決める方式で、基本的には言葉の意味の論理を数値化する方法でした。ところが、Googleは学術論文の参考文献の構造に着想を得て、そこに新たに被リンク数を追加し、「Page Rank」というアルゴリズムに基づいて検索結果の順位を決めるようにしていました。たくさんの論文に参照される論文が優れた論文であるように、多くのウェブサイトにリンクされているウェブサイトは信頼性のある良いサイトだろう、と考えてより上位に表示させるようにしたわけです。その結果、検索結果に表示されるウェブサイトの検索語句との関連性が飛躍的に向上しました。「Page Rank」の「Page」はウェブページ(Web Page)の「Page」と開発者兼創業者のラリー・ペイジ(Larry Page)の「Page」をかけています。
Infoseekで検索エンジンに取り組んだ後だけに、Googleの検索エンジンとしての技術の高さに驚きましたね。
第19話に続きます。